All Things Data
Just coming off an amazing week with a ton of information in the Hadoop Ecosystem. It’s been a 2 years since I’ve been to this conference. Somethings have changed like the name from Hadoop Summit to DataWorks Summit. Other things stayed the same like breaking news and extremely great content.
I’ll try to sum up my thoughts from the sessions I attended and people I talked with.
First there was an insanely great session called The Future Architecture of Streaming Analytics put on by a very handsome Hadoop Guru, Thomas Henson. It was a well received session where I talked about how to architect streaming application for the next 2-5 years where we will see some 20 billion plus connected devices worldwide.

Hortonwork & IBM Partnership
Next there was breaking news with Hortonworks and IBM partnerships. The huge part of the partnership was that IBM’s BigInsights will merge with Hortonworks Data Platform. Both IBM and Hortonworks are part of the open data platform .
What does this mean to the Big Data community? Well more consolidation of Hadoop distros packages, but more collaboration into the big data frameworks. This is good for the community because it allows us to focus on the open-source frameworks inside the big data community. Now instead of having to work though the difference of BigInsights vs. HDP, development will be poured into Spark, Ambari, HDFS, etc.
Hadoop 3.0 Community Updates
New updates coming the with the next release of Hadoop 3.0 was great! There is a significant amount of changes coming with the release which is slated for GA August 15, 2017. The big focus is going to be with the introduction of Erasure Coding for data striping, supporting containers for YARN, and some minor changes. Look for an in-depth look at Hadoop 3.0 in a follow up post.
Hive LLAP
If you haven’t looked deeply at Hive in the last year or so….you’ve really missed out. Hive is really starting to mature to a EDW on Hadoop!! I’m not sure how many different breakout sessions there were on Hive LLAP but I know it was mentioned in most I attended.
The first Hive breakout session was hosted by Hortonworks Co-founder Alan Gates. He walked through the latest updates and future roadmap for Hive. Also the audience was posed a question: What do we except in a Data Warehouse?
- Governance
- High Performance
- Management & Monitoring
- Security
- Replication & DR
- Storage Capacity
- Support for BI
We walked through where the Hive community was in addressing these requirements. Hive LLAP was certainly there on the higher performance. More on that now….
Another breakout session focused on a shoot off for the Hadoop SQLs. Wow this session was full and very interesting. Here is the list of SQL engines tested in the shoot out:
- MapReduce
- Presto
- Spark SQL
- Hive LLAP
All the test were run using the Hive Benchmark Testing on the same hardware. Hive LLAP was the clear winner with MapReduce the huge loser (no surprise here). The Spark SQL performed really well but there were issues using the thrift server which might have skewed the results. Kerberos was not implemented on the testing as well.
Pig Latin Updates
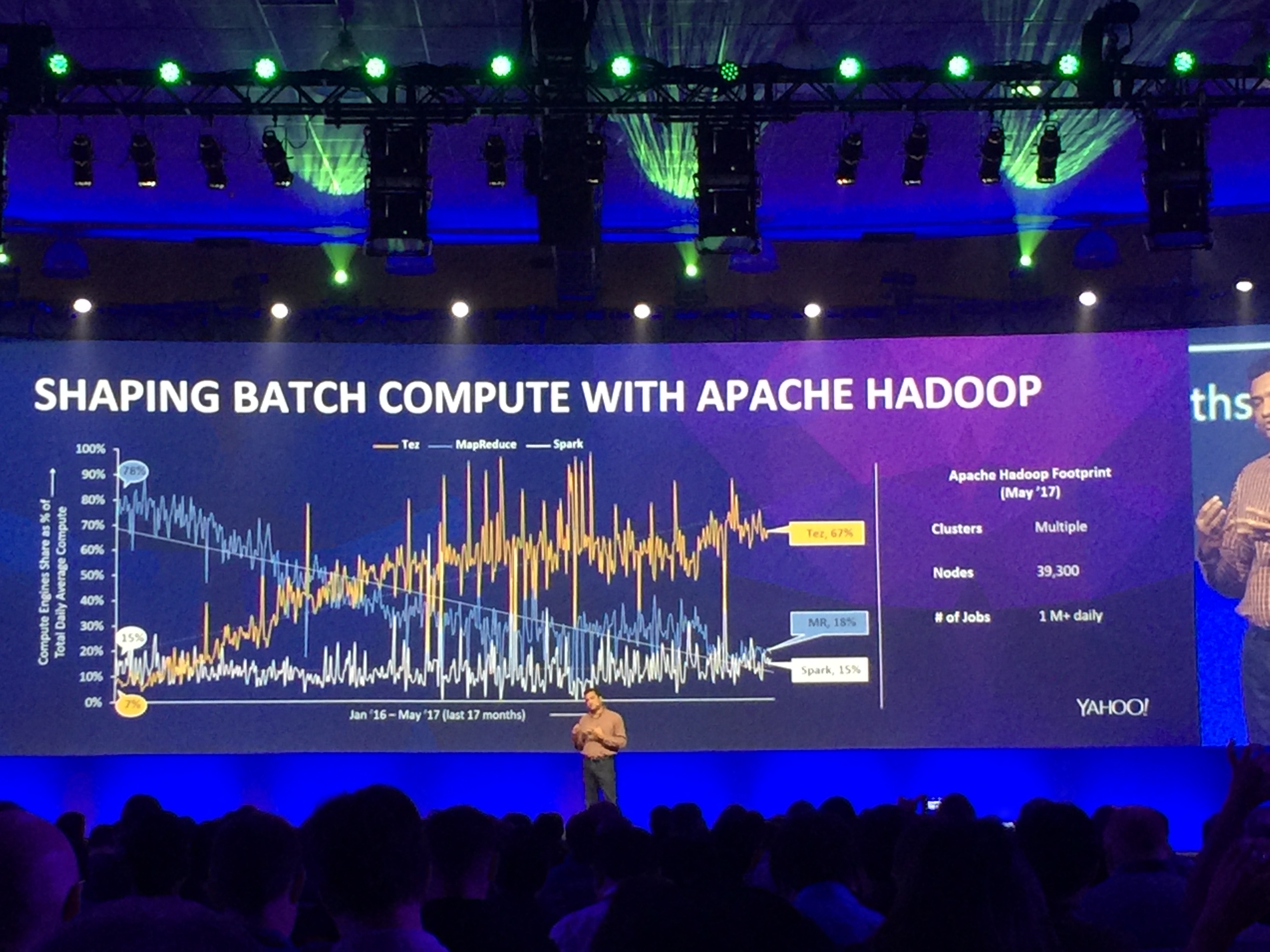
Of course there were sessions on Pig Latin! Yahoo presented their results on converting all Pig jobs from MapReduce to Tez jobs. After seeing the keynote about Yahoo’s conversation rate from MapReduce jobs to Tez/Spark/etc jobs shows that Yahoo is still running a ton of Pig jobs. Moving to Tez has increased the speed and efficiency of the Pig jobs at Yahoo. Also in the next few months Pig on Spark should be released.
Closing Thoughts
After missing last year at the Hadoop Summit or DataWorks Summit it was fun to be back. DataWorks Summit is still the premier events for Hadoop developer/admins to come and learn new features developed by the community. For sure this year the theme seemed to be benchmark testing, mix between Streaming Analytics, and Big Data EDW. It’s definitely an event I will try to make again next year to keep up with the Hadoop community.